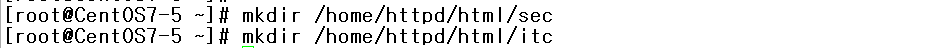• 네트워크를 통해 파티션을 공유하도록 제공하는 서비스 • Sun사에서 개발되어 대부분의 유닉스에서 사용 • 유닉스 계열의 거의 모든 시스템에서 공유 가능 • 시스템의 리소스를 직접 제공하는 서비스이므로 보안에 주의한다. - 응용을 제공하는 것이 아니라 리소스를 제공하는 서비스이다.
NFS 설치
이미 설치되어 있다.
NFS 서버 설치 확인 # rpm -qa | grep nfs-utils nfs-utils-1.2.3-64.el6.x86_64 nfs-utils-lib-1.1.5-11.el6.x86_64 # rpm -qa | grep rpcbind rpcbind-0.2.0-13.el6_9.1.x86_64
관련 파일
• 데몬 : /usr/sbin/exportfs /usr/sbin/rpcbind • 관리 스크립트 : /usr/lib/systemd/system/nfs.service //ntsysv 에서 nfs.service 선택하기 /usr/lib/systemd/system/rpcbind.service • 환경 설정 파일 : /etc/exports 이전 버전은 portmap을 이용한다. (rpcbind 대신에)
NFS 서버 실행
# systemctl start nfs.service • 관련 패키지인 nfs-server.service는 자동으로 실행된다.
NFS 서버 - exports
NFS로 제공될 자원과 권한 설정 형식 [export 할 디렉토리] [허가할 클라이언트][(옵션)] • 허가할 클라이언트 지정 - 주소/넷마스크의 표현 형식으로 사용가능 ex. 203.228.182.0/24 --> 203.228.182네트워크의 모든 주소 - 하나의 IP 및 호스트의 주소로 적을 수 있다. *, ?등의 와일드카드를 이용 여러 서버를 나타낼 수 있다. ex. *.msmc.or.kr --> msmc 도메인에 있는 모든 서버
- anonuid=uid, anongid=gid : nobody로 매핑 될경우 지정된 계정이나 그룹으로 대상을 변경한다. - sync : 파일 쓰기 후에 디스크 동기화 - insecure : 인증되지 않은 접속도 허용 ※ 서버-클라이언트간 계정 매핑은 UID를 기준으로 한다.
NFS 클라이언트 - mount
• 명령 mount –t nfs NFS서버IP:/공유디렉토리 /마운트할디렉토리 ex) mount 192.168.10.31:/home/pub /home/pub - 일반 mount와 동일하다. - 재귀적인 mount는 불허된다.
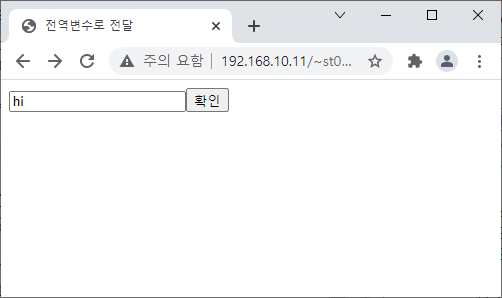
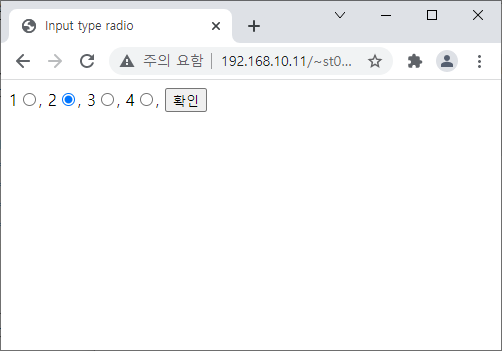
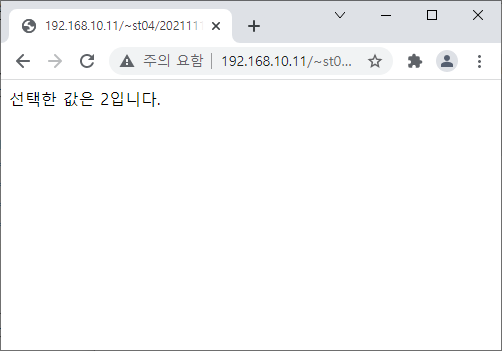
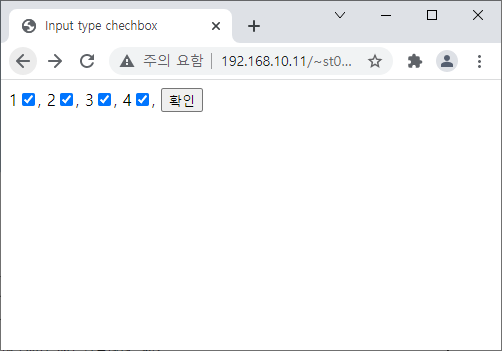
<?
$text = $_POST['text'];
echo("전달된 값은 {$text}입니다.");
?>
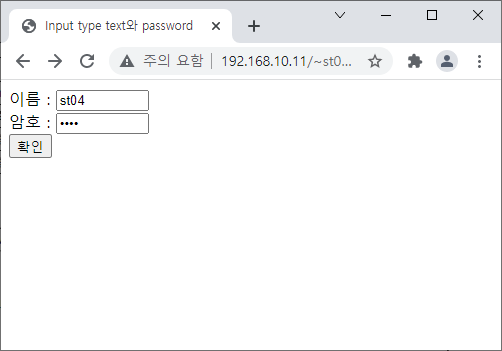
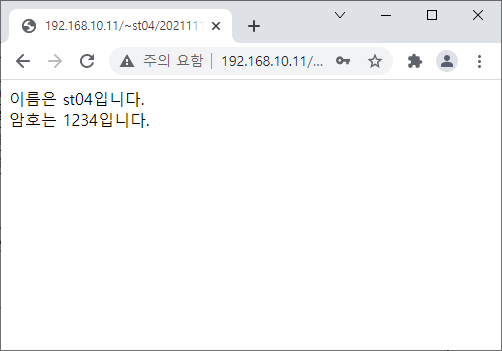
* register_globals php.ini파일에 register_globals의 역할은 EGPCS(Environment, GET, POST, Cookie, Server)의 값들을 자동으로 PHP에 전역변수로 저장해주는 옵션이다. EGPCS에 의해서 전달된 값들은 각각 연관 배열인 $_ENV, $_GET, $_POST, $_COOKIE, $_SERVER에 저장된다. 이때 전달 킷값과 동일한 변수를 전역변 수로 만들어줄려면 register_globals를 On으로 지정하면 된다.
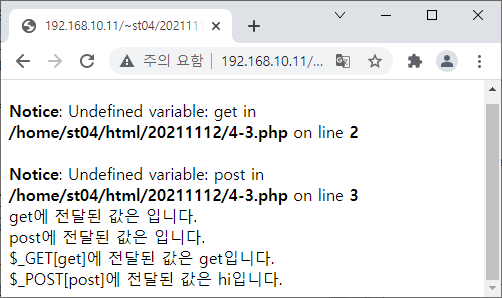
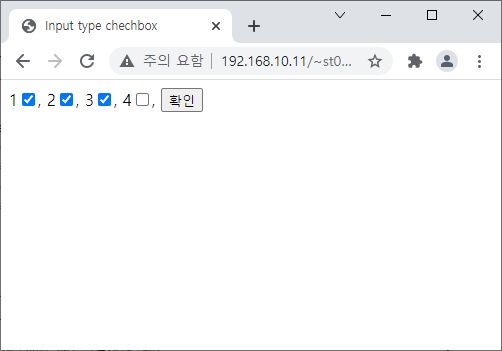
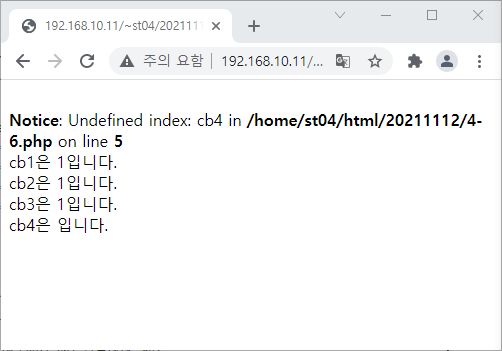
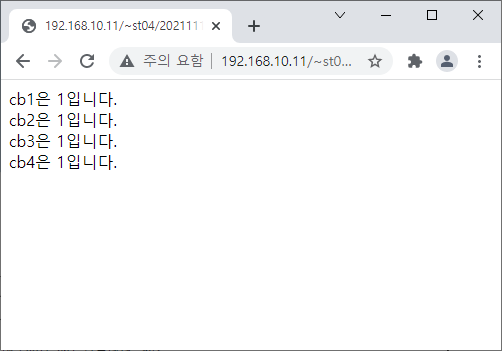
<?
echo("get에 전달된 값은 {$get}입니다.<br>
post에 전달된 값은 {$post}입니다.<br>
\$_GET[get]에 전달된 값은 {$_GET['get']}입니다.<br>
\$_POST[post]에 전달된 값은 {$_POST['post']}입니다.
");
?>
CREATE TABLE 테이블 (
컬럼 데이터_타입 [DEFAULT default값] [컬럼 레벨 제약조건],
컬럼 데이터_타입 [DEFAULT default값] [컬럼 레벨 제약조건],
......
[테이블 레벨 제약조건],
.....
);
- 데이터_타입 : 컬럼에 입력될 데이터의 종류와 크기를 결정한다. - DEFAULT : 입력이 누락됐을 때 기본 입력 값을 정의한다. : Default 값을 지정하지 않으면 널 값이 저장된다. - 컬럼 레벨 제약 조건 : PK, FK, UK, CHECK, NOT NULL등을 지정한다. - 테이블 레벨 제약 조건 : PK, FK, UK, CHECK만 지정한다. : NOT NULL은 정의할 수 없다.
DROP TABLE 테이블
[CASCADE CONSTRAINT];
PURGE RECYCLEBIN; //휴지통 비우기
SELECT table_name
FROM user_tables; //내가 소유하고 있는 table만 보고 싶을 경우
SELECT table_name, column_name, data_type, data_length
FROM user_tab_columns
[WHERE table_name = '테이블']; //'테이블' 여기서 따옴표 안 테이블 명은 무조건 대문자로 적기!
▶ 테이블 생성에서 이름 규칙 - 문자로 시작한다. - 30자 이내로 한다. - 영문, 숫자, _, $, #만을 사용한다. (한글 사용은 가능하지만 되도록 사용하지 않는 것이 좋다.) - 테이블의 이름은 동일한 유저(스키마) 안에서 유일해야 한다. - 예약어는 사용이 불가능하다. - 대소문자를 구별하지 않는다.
(생성할 때 사용한 문자와는 관계없이 모든 이름은 대문자로 정의된다.) (테이블 이름은 딕셔너리에 저장되는데, 모두 대문자로 저장된다.)
(따옴표 안에 있는 대소문자는 구별한다.)
▶ 데이터 타입 - 오라클은 다양한 데이터 타입을 제공한다. 다음은 그 중 많이 사용되는 데이터 타입들이다. - 문자 타입 : VARCHAR2, CHAR, LONG, CLOB (CHAR 타입은 안 써도 된다.) - 숫자 타입 : NUMBER - 날짜 타입 : DATE - 이진 타입 : RAW, LONG RAW, BLOB, BFILE - ROWID 타입 : ROWID
예제 1. 다음과 같은 구조의 테이블을 생성한다.(데이터 타입은 입력될 내용에 따라 결정한다.) * 테이블명 : board - 컬럼 구성 : no(게시물번호), name(작성자), sub(제목), content(내용), hdate(입력일시)
CREATE TABLE board (
no NUMBER,
name VARCHAR2(50),
sub VARCHAR2(100),
content VARCHAR2(4000),
hdate DATE DEFAULT SYSDATE
);
테이블이 생성되었습니다.
SELECT table_name FROM user_tables
WHERE table_name = 'BOARD';
TABLE_NAME
-------------
BOARD
DESC board;
이름 널? 유형
---------------- -------- ----------------
NO NUMBER
NAME VARCHAR2(50)
SUB VARCHAR2(100)
CONTENT VARCHAR2(4000)
HDATE DATE
COL table_name FORMAT A10
COL column_name FORMAT A10
COL data_type FORMAT A10
SELECT table_name, column_name, data_type, data_length
FROM user_tab_columns
WHERE table_name = 'BOARD';
TABLE_NAME COLUMN_NAM DATA_TYPE DATA_LENGTH
---------- ---------- ---------- -----------
BOARD NO NUMBER 22
BOARD NAME VARCHAR2 50
BOARD SUB VARCHAR2 100
BOARD CONTENT VARCHAR2 4000
BOARD HDATE DATE 7
INSERT INTO board (no) VALUES (1);
1 개의 행이 만들어졌습니다.
COMMIT;
커밋이 완료되었습니다.
SELECT * FROM board;
NO NAME SUB CONTENT HDATE
---------- ---------- ---------- ---------- ----------
1 2021/11/18
▶ 데이터 딕셔너리(Data Dictionary) 데이터 딕셔너리는 데이터베이스의 상태나 내부 운영과 관련된 정보를 저장해주는 테이블이다.
▶ 딕셔너리 이름의 접두어 - DBA_ : 관리자만 검색 가능한 딕셔너리에 붙는 접두어 (DBA_TABLES, DBA_INDEXES, DBA_TABLESPACES, DBA_DATA_FILES ...) - ALL_ : 일반 사용자가 검색 가능한 딕셔너리, 접근 가능한 개체에 대한 정보를 담고 있다. (ALL_TABLES, ALL_CONSTRAINTS, ALL_INDEXES, ALL_VIEWS, ...) - USER_ : 일반 사용자가 검색 가능한 딕셔너리, 소유하고 있는 개체에 대한 정보를 담고 있다. (USER_TABLES, USER_CONSTRAINTS, USER_INDEXES, USER_VIEWS, ...)
예제 2. 테이블을 생성하고 데이터를 입력 확인한다.
SQL> CREATE TABLE t1 (no NUMBER(4,2));
테이블이 생성되었습니다.
SQL> INSERT INTO t1 VALUES (12.12);
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO t1 VALUES (1.789);
1 개의 행이 만들어졌습니다.
SQL> SELECT * FROM t1;
NO
----------
12.12
1.79
SQL> INSERT INTO t1 VALUES (123.1);
INSERT INTO t1 VALUES (123.1)
*
1행에 오류:
ORA-01438: 이 열에 대해 지정된 전체 자릿수보다 큰 값이 허용됩니다.
SQL> CREATE TABLE t2 (name VARCHAR2(3));
테이블이 생성되었습니다.
SQL> INSERT INTO t2 VALUES ('AAA');
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO t2 VALUES ('장강');
INSERT INTO t2 VALUES ('장강')
*
1행에 오류:
ORA-12899: "ST"."T2"."NAME" 열에 대한 값이 너무 큼
SQL> INSERT INTO t2 VALUES ('장');
1 개의 행이 만들어졌습니다.
SQL> SELECT * FROM t2;
NAME
----
AAA
장
예제 3. 다음 예제를 통해 CHAR와 VARCHAR2의 차이를 이해해 보자
SQL> CREATE TABLE comp(
2 co1 CHAR(4),
3 co2 VARCHAR2(4)
4 );
테이블이 생성되었습니다.
SQL> INSERT INTO comp VALUES ('AA','AA');
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO comp VALUES ('AAAA','AAAA');
1 개의 행이 만들어졌습니다.
SQL> SELECT LENGTHB(co1), LENGTHB(co2) FROM comp;
LENGTHB(CO1) LENGTHB(CO2)
------------ ------------
4 2
4 4
SQL> SELECT * FROM comp;
CO1 CO2
-------- --------
AA AA
AAAA AAAA
SQL> SELECT * FROM comp WHERE co1='AA';
CO1 CO2
-------- --------
AA AA
SQL> SELECT * FROM comp WHERE co2='AA';
CO1 CO2
-------- --------
AA AA
SQL> SELECT * FROM comp WHERE co1=co2;
CO1 CO2
-------- --------
AAAA AAAA
예제 4. 다음 실습을 통해 DATE 타입에 대해서 이해해 보자
CREATE TABLE hd (
no NUMBER,
hdate DATE
);
테이블이 생성되었습니다.
SQL> INSERT INTO hd VALUES (1, sysdate);
1 개의 행이 만들어졌습니다.
SQL> SELECT * FROM hd;
NO HDATE
---------- ----------
1 2021/11/19
SQL> SELECT * FROM hd WHERE hdate = '2021/11/19';
선택된 레코드가 없습니다.
SQL> SELECT no, TO_CHAR(hdate,'YYYY/MM/DD:HH24:MI:SS') FROM hd;
NO TO_CHAR(HDATE,'YYYY/MM/DD:HH24:MI:SS')
---------- --------------------------------------
1 2021/11/19:13:21:42
SQL> SELECT * FROM hd
2 WHERE hdate BETWEEN '2021/11/19' AND '2021/11/20';
NO HDATE
---------- ----------
1 2021/11/19
SQL> SELECT * FROM hd
2 WHERE TRUNC(hdate) = '2021/11/19';
NO HDATE
---------- ----------
1 2021/11/19
SQL> SELECT * FROM hd
2 WHERE hdate like '2021/11/19%'; // 답은 나오지만 사용하지 말기
NO HDATE
---------- ----------
1 2021/11/19
테이블 생성시 아래와 같이 만든다.
예제 5. 다음에 제시된 테이블을 생성한다. 테이블명이나 컬럼의 이름, 컬럼의 길이는 임의로 정한다. - 테이블명 : 고객 - 컬럼 : 고객관리번호, 고객명, 주소, 전화 * C:\Users\st04\sql\client.sql 파일 생성
client.sql
DROP TABLE client;
PURGE RECYCLEBIN;
CREATE TABLE client(
cnum NUMBER,
cname VARCHAR2(50),
addr VARCHAR2(200),
tel VARCHAR2(20)
);
@C:\Users\st04\sql\client
SQL> @client
DROP TABLE client
*
1행에 오류:
ORA-00942: 테이블 또는 뷰가 존재하지 않습니다
휴지통이 지워졌습니다.
테이블이 생성되었습니다.
실습
1. 예제를 통해 만들어진 테이블을 확인하고 모두 삭제한다.
SQL> DESC client;
이름 널? 유형
-------------------------- -------- -------------------------
CNUM NUMBER
CNAME VARCHAR2(50)
ADDR VARCHAR2(200)
TEL VARCHAR2(20)
SQL> DROP TABLE client;
테이블이 삭제되었습니다.
SQL> DESC client;
ERROR:
ORA-04043: client 객체는 존재하지 않습니다.
2. 다음 구조와 같은 테이블을 생성하는 스크립트를 작성하고 실행해본다. - 테이블명이나 컬럼명, 데이터 타입 등은 입력될 데이터의 성격에 따라 임의로 정할 수 있다.
: 업무 기본 단위, 반드시 한꺼번에 처리해야하는 단위 (데이터베이스) (* 정보보안에서는 함수, 정보 등으로 해석 )
◾ 원자성(Aotomicity) - 트랜잭션은 최소의 작업 단위로서 전체가 처리되거나 취소될 수 있지만 일부만 처리될 수 없다. ◾ 일관성(Consistency) - 트랜잭션이 실행된 이후 데이터베이스의 무결성은 반드시 유지돼야 한다. ◾ 독립성(Isolation) → Lock 과 관련 - 트랜잭션을 여러 개 동시에 실행하더라도 각각의 트랜잭션은 서로 영향을 줄 수 없다. 즉 실행이 종료되지 않은 트랜잭션의 결과는 다른 트랜잭션에서 참조하는 것이 불가능하다. ◾ 영속성(Durability) - 종료된 트랜잭션의 결과는 반드시 데이터베이스에 반영돼야 한다.
▶ 트랜잭션의 시작과 종료 ①시작 - 이전 트랜잭션이 종료된 이후 DML(INSERT, UPDATE, DELETE)문장이나 DDL(CREATE, ALTER, DROP, TRUNCATE), DCL(GRANT, REVOKE)문장에 실행됐을 때 시작된다. ②종료 - COMMIT이나 ROLLBACK 명령이 실행 될 때 종료된다. - DDL이나 DCL문장의 실행이 완료되면 자동으로 종료된다. - 사용자의 정상 종료 시에 종료된다. - 데드락(Deadlock)이 걸리면 트랜잭션의 일부만 종료된다.
▶ 트랜잭션 과정
▶ 독점 잠금(Exclusive lock)과 공유 잠금(Share lock) 독점 잠금은 현재 세션이외에는 접근을 불허하는 잠금이다. 이는 트랜잭션의 특징인 독립성을 보장하기 위한 것이다. 트랜잭션으로 행에 잠금이 발생하면 다른 세션에서는 해당 행을 검색할 수 없고 단지 언 두 세그먼트의 정보만 보게 된다. 그리고 이때 테이블에는 공유 잠금이 발생하는데 이것은 DML작업으 로 행이 잠겨있는 테이블에 대해서 DDL(DROP, ALTER)작업을 방지한다. 공유 잠금은 독점 잠금이 걸 린 행 이외 행에 대한 접근을 방해하지 않는다.
예제 1. 트랜잭션과 잠금의 이해 * 실습에는 두 개의 일반 사용자 세션이 사용된다. - 동일한 st 계정으로 접속한 Sqlplus창을 두 개 실행한다. - 두 개의 창은 [세션 1]과 [세션 2]로 구분한다.
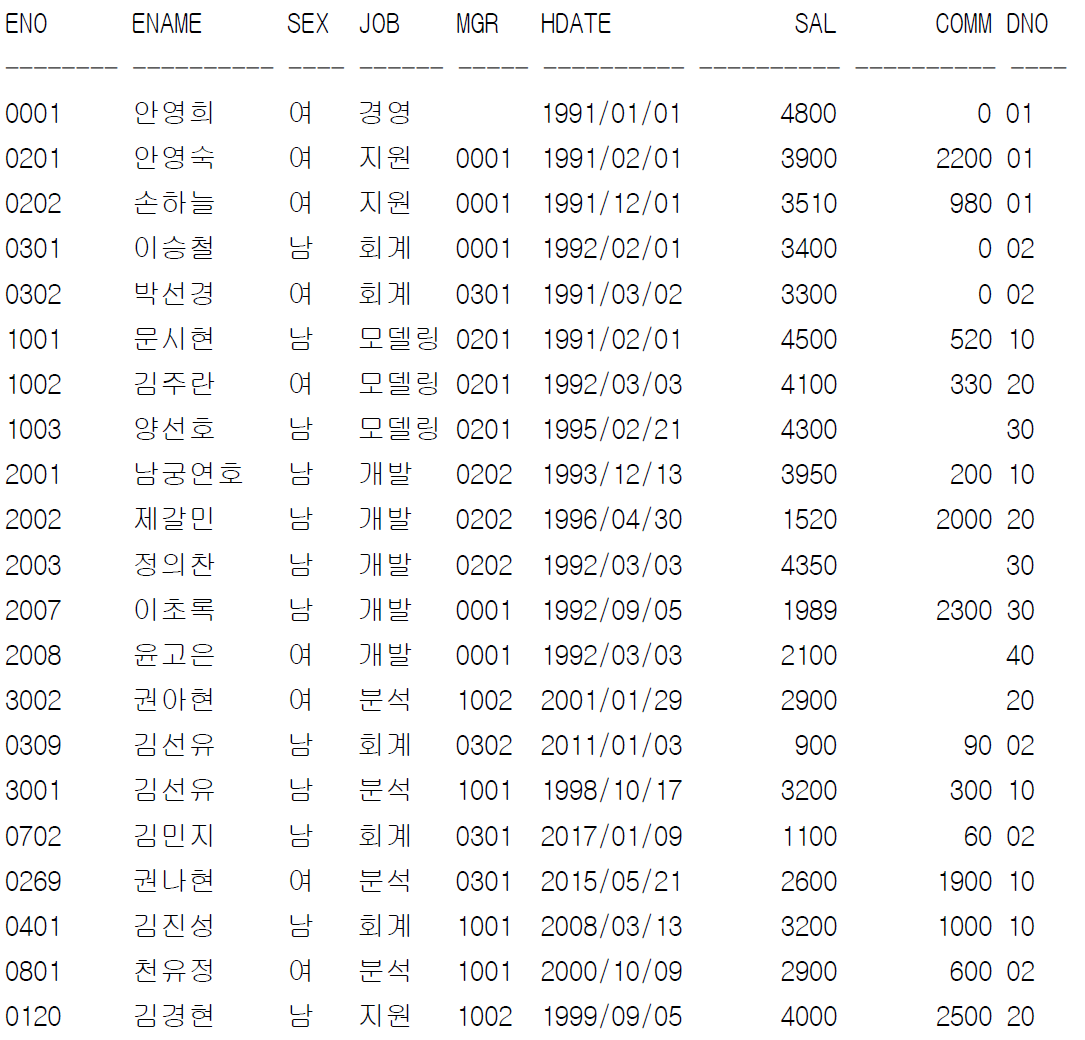
[세션 1] commit 전
SELECT eno, ename, sal FROM emp
WHERE ename = '문시현';
ENO ENAME SAL
------- ---------- ----------
1001 문시현 4500
UPDATE emp SET sal = sal*2
WHERE ename = '문시현';
1 행이 업데이트되었습니다.
SELECT eno, ename, sal FROM emp
WHERE ename = '문시현';
ENO ENAME SAL
------- ---------- ----------
1001 문시현 9000
[세션2] commit 전
SELECT eno, ename, sal FROM emp
WHERE ename='문시현';
ENO ENAME SAL
------- ---------- ----------
1001 문시현 4500
[세션1] commit 후
COMMIT;
커밋이 완료되었습니다.
[세션2] commit 후
SELECT eno, ename, sal FROM emp
WHERE ename = '문시현';
ENO ENAME SAL
------- ---------- ----------
1001 문시현 9000
데이터를 읽는 것은 내가 select 문을 실행할 때 commit 된 데이터만 보는 것
예제 2. 트랜잭션에 의한 대기 현상 확인 * 환경은 [예제 1]과 동일하다.
[세션 1] commit 전
SELECT eno, ename, sal FROM emp
WHERE ename = '안영희';
ENO ENAME SAL
------- ---------- ----------
0001 안영희 4800
UPDATE emp SET sal = sal * 1.5
WHERE ename = '안영희';
1 행이 업데이트되었습니다.
SELECT eno, ename, sal FROM emp
WHERE ename = '안영희';
ENO ENAME SAL
------- ---------- ----------
0001 안영희 7200
[세션 2] commit 전
SELECT eno, ename, sal FROM emp
WHERE ename = '안영희';
ENO ENAME SAL
------- ---------- ----------
0001 안영희 4800
UPDATE emp SET comm = 900
WHERE ename = '안영희';
↑ 대기상태에 빠진다.
세션 1이 commit 가 되지 않아 대기상태에 빠진다.
[세션 1] commit 후
COMMIT;
커밋이 완료되었습니다.
SELECT eno, ename, sal, comm FROM emp
WHERE ename = '안영희';
ENO ENAME SAL COMM
------- ---------- ---------- ----------
0001 안영희 7200 0
[세션 2] commit 후
UPDATE emp SET comm = 900
WHERE ename = '안영희';
1 행이 업데이트되었습니다.
COMMIT;
커밋이 완료되었습니다.
[세션 1] commit 후
SELECT eno, ename, sal, comm FROM emp
WHERE ename = '안영희';
ENO ENAME SAL COMM
------- ---------- ---------- ----------
0001 안영희 7200 900
예제 3. 데드락(Dead Lock)을 발생하고 RDBMS의 처리 과정을 확인한다. * 환경은 [실습 1]과 동일하다. * [세션 1]과 [세션 2]는 각각 서로 다른 행에 독점 잠금을 걸고 서로 상대 트랜잭션이 독점 잠금을 걸어둔 행에 DML을 실행해 본다.
[세션 1]
SELECT eno, ename, dno FROM emp
WHERE ename IN ('안영희','문시현');
ENO ENAME DNO
------- ---------- -------
0001 안영희 01
1001 문시현 10
UPDATE emp SET dno = '02'
WHERE ename = '안영희';
1 행이 업데이트되었습니다.
SELECT eno, ename, dno FROM emp
WHERE ename IN ('안영희','문시현');
ENO ENAME DNO
------- ---------- -------
0001 안영희 02 ←← 독점 잠금
1001 문시현 10
[세션 2]
SELECT eno, ename, dno FROM emp
WHERE ename IN ('안영희','문시현');
ENO ENAME DNO
------- ---------- -------
0001 안영희 01
1001 문시현 10
UPDATE emp SET dno = '20'
WHERE ename = '문시현';
1 행이 업데이트되었습니다.
SELECT eno, ename, dno FROM emp
WHERE ename IN ('안영희','문시현');
ENO ENAME DNO
------- ---------- -------
0001 안영희 01
1001 문시현 20 ←← 독점 잠금
UPDATE emp SET sal = sal * 1.5
WHERE ename = '안영희';
↑ 대기상태에 빠짐
[세션 1]
UPDATE emp SET sal = sal * 1.5
WHERE ename = '문시현';
↑ 대기상태에 빠짐
[세션 2]
UPDATE emp SET sal = sal * 1.5
WHERE ename = '안영희';
↑ 대기상태에 빠짐
[세션 1]
UPDATE emp SET sal = sal * 1.5
WHERE ename = '문시현';
↑ 대기상태에 빠짐
세션 2 에서 update 실행 후 아래와 같이 에러가 뜬다.
UPDATE emp SET sal = sal * 1.5
*
1행에 오류:
ORA-00060: 자원 대기중 교착 상태가 검출되었습니다
예제 1. Dept 테이블의 모든 데이터를 삭제한 다음 ROLLBACK을 수행한 다음 결과를 확인한다.
DELETE FROM dept;
7 행이 삭제되었습니다.
SELECT * FROM dept;
선택된 레코드가 없습니다.
ROLLBACK;
롤백이 완료되었습니다.
SELECT * FROM dept;
DNO DNAME LOC
------- ------- -----
01 총무 서울
02 회계 서울
10 ERP 서울
20 ISP 부산
30 ITEA 광주
40 CRM 대전
50 POS
예제 2. Emp와 dept 테이블의 모든 데이터를 삭제한다.
DELETE FROM dept;
7 행이 삭제되었습니다.
DELETE FROM emp;
21 행이 삭제되었습니다.
SELECT * FROM dept;
선택된 레코드가 없습니다.
SELECT * FROM emp;
선택된 레코드가 없습니다.
COMMIT;
커밋이 완료되었습니다.
예제 3. EMP 테이블에 아래 제공된 값을 입력한다.
ALTER SESSION SET nls_date_format='YYYY/MM/DD';
세션이 변경되었습니다.
DESC emp;
이름 널? 유형
----------------- -------- ------------------------------------
ENO VARCHAR2(4)
ENAME VARCHAR2(15)
SEX VARCHAR2(4)
JOB VARCHAR2(12)
MGR VARCHAR2(4)
HDATE DATE
SAL NUMBER
COMM NUMBER
DNO VARCHAR2(2)
INSERT INTO emp (eno, ename, sex, job, mgr, hdate, sal, comm, dno)
VALUES ('1001', '문시현', '남', '모델링', NULL, '1991/02/01', 4500, 520, '10');
//이렇게 사용!!!
1 개의 행이 만들어졌습니다.
INSERT INTO emp (eno, ename, sex, job, hdate, sal, comm, dno)
VALUES ('1002', '김주란', '여', '모델링', '1992/03/03', 4100, 330, '20');
//사용하지 말기
1 개의 행이 만들어졌습니다.
INSERT INTO emp
VALUES ('1003', '양선호', '남', '모델링', NULL, '1995/02/21', 4300, NULL, '30');
//사용하지 말기
1 개의 행이 만들어졌습니다.
COMMIT;
커밋이 완료되었습니다.
SELECT * FROM emp;
ENO ENAME SEX JOB MGR HDATE SAL COMM DNO
------- ---------- --- ------- ------- ---------- ---------- ---------- -------
1001 문시현 남 모델링 1991/02/01 4500 520 10
1002 김주란 여 모델링 1992/03/03 4100 330 20
1003 양선호 남 모델링 1995/02/21 4300 30
0001 안영희 여 경영 1991/01/01 10800 900 02
0201 안영숙 여 지원 0001 1991/02/01 3900 2000 01
0202 손하늘 여 지원 0001 1991/12/01 3510 980 01
0301 이승철 남 회계 0001 1992/02/01 3400 0 02
예제 4. Emp 테이블의 모든 데이터를 삭제하고 아래 제공된 값을 입력한다.
SELECT sysdate FROM dual;
SYSDATE
----------
2021/11/18
INSERT INTO emp (eno, ename, hdate)
VALUES ('5001', '안영희', '1991/01/03:07:15:25');
VALUES ('5001', '안영희', '1991/01/03:07:15:25')
*
2행에 오류:
ORA-01830: 날짜 형식의 지정에 불필요한 데이터가 포함되어 있습니다
ALTER SESSION SET nls_date_format = 'YYYY/MM/DD:HH24:MI:SS';
세션이 변경되었습니다.
INSERT INTO emp (eno, ename, hdate)
VALUES ('5001', '안영희', '1991/01/03:07:15:25');
1 개의 행이 만들어졌습니다.
SQL> COMMIT;
커밋이 완료되었습니다.
예제 5. 날짜 형식을 확인하고 아래 제공된 값을 입력한다. 날짜 입력에 TO_DATE()를 이용한다.
SQL> ALTER SESSION SET nls_date_format='YYYY-MM-DD:HH24:MI:SS';
세션이 변경되었습니다.
SQL> INSERT INTO emp (eno,hdate) VALUES ('01', TO_DATE('2000', 'YYYY'));
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO emp (eno,hdate) VALUES ('02', TO_DATE('99', 'YY'));
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO emp (eno,hdate) VALUES ('03', TO_DATE('99', 'RR'));
1 개의 행이 만들어졌습니다.
SQL> COMMIT;
커밋이 완료되었습니다.
SQL> SELECT eno, hdate FROM emp
2 ORDER BY 1;
ENO HDATE
------- -------------------
0001 1991-01-01:00:00:00
01 2000-11-01:00:00:00
0120 1999-09-05:00:00:00
02 2099-11-01:00:00:00
0201 1991-02-01:00:00:00
0202 1991-12-01:00:00:00
0269 2015-05-21:00:00:00
예제 7. 김주란의 부서 번호를 10번으로 수정하고 급여를 10% 인상하세요 - 수행 전 실습용 테이블을 초기화한다.
@C:\Users\st04\sql\school_euc
SELECT * FROM emp WHERE ename = '김주란';
ENO ENAME SEX JOB MGR HDATE SAL COMM DNO
------- ---------- --- ------- ------- ---------- ---------- ---------- -------
1002 김주란 여 모델링 0201 1992/03/03 4100 330 20
UPDATE emp SET dno = '10', sal = sal*1.1
WHERE ename = '김주란';
1 행이 업데이트되었습니다.
SQL> COMMIT;
커밋이 완료되었습니다.
SELECT * FROM emp WHERE ename = '김주란';
ENO ENAME SEX JOB MGR HDATE SAL COMM DNO
------- ---------- --- ------- ------- ---------- ---------- ---------- -------
1002 김주란 여 모델링 0201 1992/03/03 4510 330 10
SELECT * FROM emp
WHERE dno = '01';
ENO ENAME SEX JOB MGR HDATE SAL COMM DNO
------- ---------- --- ------- ------- ---------- ---------- ---------- -------
0001 안영희 여 경영 1991/01/01 4800 0 01
0201 안영숙 여 지원 0001 1991/02/01 3900 2000 01
0202 손하늘 여 지원 0001 1991/12/01 3510 980 01
UPDATE emp SET sal = sal * 1.1
WHERE dno = '01';
3 행이 업데이트되었습니다.
COMMIT;
커밋이 완료되었습니다.
SELECT * FROM emp
WHERE dno = '01';
ENO ENAME SEX JOB MGR HDATE SAL COMM DNO
------- ---------- --- ------- ------- ---------- ---------- ---------- -------
0001 안영희 여 경영 1991/01/01 5280 0 01
0201 안영숙 여 지원 0001 1991/02/01 4290 2000 01
0202 손하늘 여 지원 0001 1991/12/01 3861 980 01
실습
1. 다음 INSERT 문을 실행하고 입력 결과를 확인한다.
* 입력값에 포함되지 않은 년도, 월, 날짜, 시, 분, 초에 입력된 값을 확인한다.
SQL> INSERT INTO emp (eno,hdate) VALUES (5, TO_DATE('12', 'MM'));
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO emp (eno,hdate) VALUES (6, TO_DATE('10', 'DD'));
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO emp (eno,hdate) VALUES (7, TO_DATE('9', 'HH24'));
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO emp (eno,hdate) VALUES (8, TO_DATE('12', 'MI'));
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO emp (eno,hdate) VALUES (9, TO_DATE('20', 'SS'));
1 개의 행이 만들어졌습니다.
SQL> INSERT INTO emp (eno,hdate) VALUES (10, sysdate);
1 개의 행이 만들어졌습니다.
SQL> ALTER SESSION SET nls_date_format='YYYY/MM/DD:HH24:MI:SS';
세션이 변경되었습니다.
SELECT * FROM EMP;
ENO ENAME SEX JOB MGR HDATE SAL COMM DNO
------- ---------- --- ------- ------- ------------------- ---------- ---------- -------
0001 안영희 여 경영 1991/01/01:00:00:00 5280 0 01
0201 안영숙 여 지원 0001 1991/02/01:00:00:00 4290 2000 01
0202 손하늘 여 지원 0001 1991/12/01:00:00:00 3861 980 01
0301 이승철 남 회계 0001 1992/02/01:00:00:00 3400 0 02
0302 박선경 여 회계 0301 1991/03/02:00:00:00 3300 0 02
1001 문시현 남 모델링 0201 1991/02/01:00:00:00 4500 520 10
1002 김주란 여 모델링 0201 1992/03/03:00:00:00 4510 330 10
...
ENO ENAME SEX JOB MGR HDATE SAL COMM DNO
------- ---------- --- ------- ------- ------------------- ---------- ---------- -------
5 2021/12/01:00:00:00
6 2021/11/10:00:00:00
7 2021/11/01:09:00:00
8 2021/11/01:00:12:00
9 2021/11/01:00:00:20
10 2021/11/18:17:23:19
2. Emp 테이블의 행을 모두 삭제하고 다음 제시된 데이터를 입력한다.
SQL> DELETE FROM EMP;
27 행이 삭제되었습니다.
INSERT INTO emp (eno, ename, sex, job, mgr, hdate, sal, comm, dno)
VALUES ('0001', '안영희', '여', '경영', NULL, TO_DATE('1991/01/01', 'YYYY/MM/DD'), 4800, 0, '01');
1 개의 행이 만들어졌습니다.
SELECT * FROM emp;
ENO ENAME SEX JOB MGR HDATE SAL COMM DNO
------- ---------- --- ------- ------- ---------- ---------- ---------- -------
0001 안영희 여 경영 1991/01/01 4800 0 01
3. 모든 학생의 성적을 4.5만 점 기준으로 수정한다.
SQL> SELECT * FROM student;
SNO SNAME SEX SYEAR MAJOR AVR
-------- ---------- ---- ---------- ------ ----------
915301 정동상 남 4 화학 .95
905301 유태지 남 4 화학 3.28
905302 정욱상 남 4 화학 1.44
915303 정욱주 남 4 화학 .95
923903 정남윤 남 3 생물 3.23
923904 한현석 남 3 생물 2.45
933901 김용서 남 2 생물 1.48
915304 권보수 남 4 화학 2.32
915305 최정희 여 3 화학 .58
948203 황보우리 여 1 식영 2.83
948204 서창동 남 1 식영 3.21
UPDATE student SET avr=avr*4.5/4;
87 행이 업데이트되었습니다.
SELECT * FROM student;
SNO SNAME SEX SYEAR MAJOR AVR
-------- ---------- ---- ---------- ------ ----------
915301 정동상 남 4 화학 1.07
905301 유태지 남 4 화학 3.69
905302 정욱상 남 4 화학 1.62
915303 정욱주 남 4 화학 1.07
923903 정남윤 남 3 생물 3.63
923904 한현석 남 3 생물 2.76
933901 김용서 남 2 생물 1.67
915304 권보수 남 4 화학 2.61
915305 최정희 여 3 화학 .65
948203 황보우리 여 1 식영 3.18
948204 서창동 남 1 식영 3.61
SELECT major 학과, syear 학년, sno 학번, sname 이름
FROM student
WHERE major='화학';
학과 학년 학번 이름
------- ---------- ------- ----------
화학 4 915301 정동상
화학 4 905301 유태지
화학 4 905302 정욱상
화학 4 915303 정욱주
화학 4 915304 권보수
화학 3 915305 최정희
화학 2 925306 김재백
DELETE FROM student WHERE major='화학' AND syear=2;
4 행이 삭제되었습니다.
SELECT major 학과, syear 학년, sno 학번, sname 이름
FROM student
WHERE major='화학';
학과 학년 학번 이름
------- ---------- ------- ----------
화학 4 915301 정동상
화학 4 905301 유태지
화학 4 905302 정욱상
화학 4 915303 정욱주
화학 4 915304 권보수
화학 3 915305 최정희
화학 1 945302 김람석
SELECT [DISTINCT/ALL] 컬럼 or 그룹함수, ...
FROM 테이블
WHERE 조건
GROUP BY Group대상
HAVING <그룹 함수 포함 조건>
ORDER BY 정렬대상 [ASC/DESC];
조건인데 그룹 함수가 포함되어있으면 having절에 기술한다.
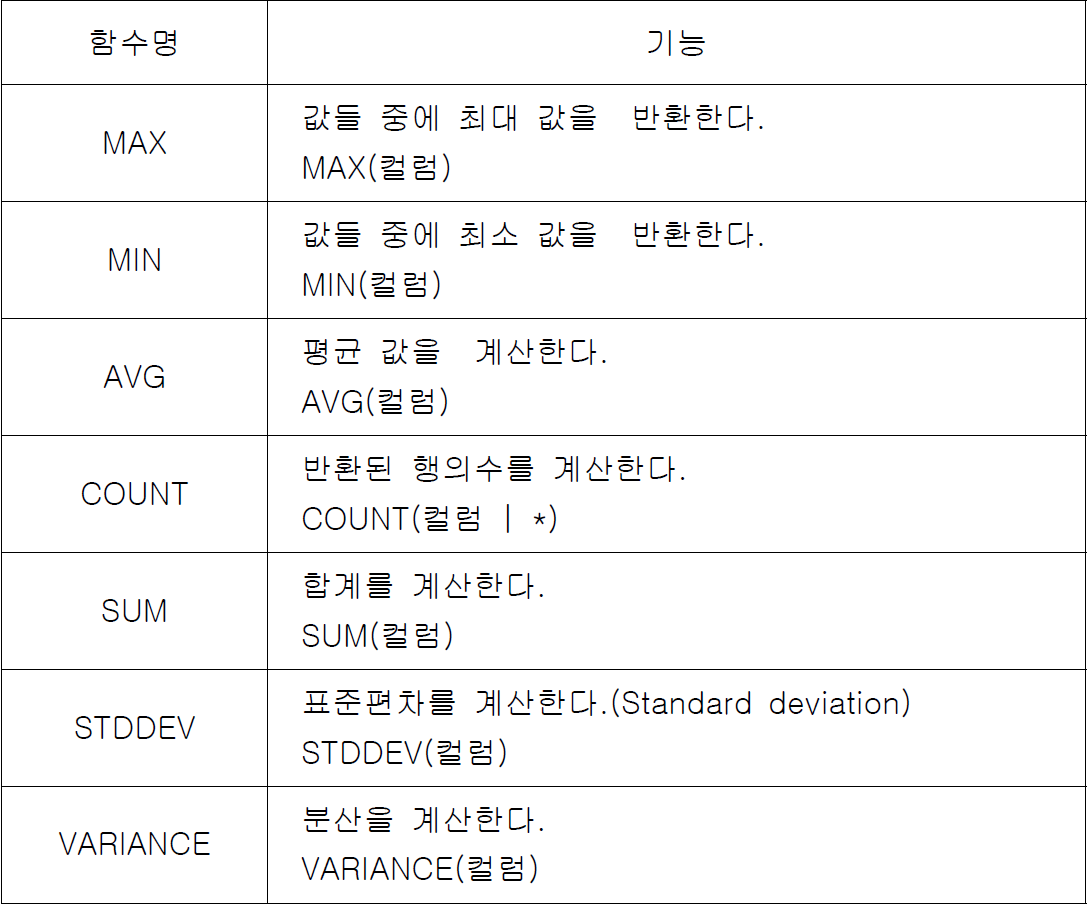
예제 1. 부서별 급여 평균이 3천 달러 미만인 부서의 부서 번호와 평균 급여를 검색한다.
SELECT dno 부서번호, ROUND(AVG(sal)) 평균급여
FROM emp
GROUP BY dno
HAVING AVG(sal) < 3000;
부서 평균급여
---- ----------
02 2320
40 2100
예제 2. HAVING절의 다양한 사용법
SELECT dno 부서번호, COUNT(*) 인원수
FROM emp
GROUP BY dno
HAVING job != '개발';
HAVING job != '개발'
*
4행에 오류:
ORA-00979: GROUP BY 표현식이 아닙니다.
SELECT dno 부서번호, COUNT(*) 인원수
FROM emp
GROUP BY dno
HAVING dno != '10'; //일반칼럼 조건인데 having절에 쓰면 안된다. 실행은 되지만 쓰지말자!
부서번호 인원수
--------- ----------
20 4
01 3
30 3
02 5
40 1
예제 3. 부서 중 가장 급여를 많이 받는 부서를 검색한다.
SELECT dno, AVG(sal)
FROM emp
GROUP BY dno
HAVING AVG(sal) = (SELECT MAX(AVG(sal))
FROM emp
GROUP BY dno);
DNO AVG(SAL)
------- ----------
01 4070
실습
1. 화학과를 제외하고 학과별로 학생들의 평점 평균을 검색한다.
SELECT major, TO_CHAR(AVG(avr), 90.99) 평점평균
FROM student
GROUP BY major
HAVING major!='화학';
MAJOR 평점평균
------- ------------
유공 2.95
생물 2.45
식영 3.25
물리 2.42
2. 화학과를 제외한 각 학과별 평균 평점 중에 평점이 2.0 이상인 정보를 검색한다.
SELECT major, TO_CHAR(AVG(avr), 90.99) 평점평균
FROM student
GROUP BY major
HAVING major!='화학' AND AVG(avr)>2.0;
MAJOR 평점평균
------- ------------
유공 2.95
생물 2.45
식영 3.25
물리 2.42
3. 기말고사 평균이 60점 이상인 학생의 정보를 검색한다.(학번과 기말고사 평균)
SELECT s.sno 학번, TO_CHAR(AVG(result), 90.99) 기말고사평균
FROM student s, score r
WHERE s.sno=r.sno
GROUP BY s.sno
HAVING AVG(result)>=60;
학번 기말고사평균
------- ------------
948204 72.19
905603 68.56
913904 65.81
913908 77.23
915305 69.47
918202 63.76
924501 68.32
4. 강의 학점수가 3학점 이상인 교수의 정보를 검색한다.(교수번호, 이름과 담당 학점수)
SELECT p.pno 교수번호, pname 이름, SUM(st_num) 학점수
FROM professor p, course c
WHERE p.pno=c.pno
GROUP BY p.pno, pname, st_num
HAVING SUM(st_num)>=3;
교수번호 이름 학점수
--------- ---------- ----------
1029 주동평 3
1013 하영진 3
1018 김응전 3
1035 장관용 3
1010 이규진 3
1017 최무송 6
1004 시진영 6
1006 장청아 3
1022 이준 6
1027 임충원 3
1008 문규식 3
1036 성현수 3
5. 기말고사 성적이 핵 화학과목보다 우수한 과목의 과목명과 담당 교수명 검색한다.
SELECT c.cno 과목번호, cname 과목이름, p.pno 교수번호, pname 교수이름
FROM professor p, course c, score r
WHERE p.pno = c.pno
AND c.cno = r.cno
AND result > ALL(SELECT result
FROM score r, course c
WHERE r.cno=c.cno
AND cname='핵화학')
GROUP BY c.cno, cname, p.pno, pname;
과목번호 과목이름 교수번호 교수이름
--------- ------------ --------- ----------
1712 분자생물학 1030 김동평
1226 양자물리학 1016 호연작
SELECT SUM(comm) 총액,
ROUND(AVG(comm)) 평균, COUNT(comm) 수령인원,
ROUND(AVG(NVL(comm,0))) 환산평균, COUNT(*) 전체인원
FROM emp;
총액 평균 수령인원 환산평균 전체인원
---------- ---------- ---------- ---------- ----------
14780 869 17 704 21
SELECT COUNT(*) FROM emp
WHERE comm IS NOT NULL;
COUNT(*)
----------
17
null 값은 무시가 되기 때문에 위 방식은 문제가 발생한다.
예제 3. 10번 부서원들보다 급여가 높은 사원을 검색한다.
SELECT eno 사번, ename 이름, dno 부서번호
FROM emp
WHERE sal > (SELECT MAX(sal) // 추천!!!
FROM emp
WHERE dno = '10');
SELECT eno 사번, ename 이름, dno 부서번호
FROM emp
WHERE sal > ALL(SELECT sal
FROM emp
WHERE dno = '10');
사번 이름 부서번호
------- ---------- ---------
0001 안영희 01
보통은 위의 두 방식 중 첫번째 방식처럼 사용한다. 단일행 서브쿼리로 사용한다.
▶ 그룹 함수와 GROUP BY절
SELECT [DISTINCT/ALL] 컬럼 or 그룹함수, ...
FROM 테이블
WHERE 조건
GROUP BY Group대상
ORDER BY 정렬대상 [ASC/DESC]
- 통계정보를 출력할 경우 같은 정보를 가진 사람끼리 통계정보를 출력하기 위해 GROUP BY 절을 사용한다.
- GROUP BY 절에 있는 컬럼 명을 SELECT절 일반컬럼에 꼭 넣어준다.
- 카디널리티: 값의 종류 (ex. 성별은 카디널리티 낮음, 이름은 카디널리티 높음)
예제 4. 업무별 평균 급여, 평균 연봉과 부서별 평균 연봉을 검색한다.
SELECT job 업무, ROUND(AVG(sal)) 평균_급여,
ROUND(AVG(sal*12+NVL(comm,0))) 평균_연봉
FROM emp
GROUP BY job;
업무 평균_급여 평균_연봉
------- ---------- ----------
분석 2900 35500
지원 3803 47467
개발 2782 34282
모델링 4300 51883
경영 4800 57600
회계 2380 28790
SELECT d.dno 부서번호, dname 부서명,
ROUND(AVG(sal*12+NVL(comm,0))) 평균_연봉
FROM dept d, emp e
WHERE d.dno = e.dno
GROUP BY d.dno, dname
ORDER BY d.dno;
부서번호 부서명 평균_연봉
--------- ------- ----------
01 총무 49833
02 회계 27990
10 ERP 42664
20 ISP 38768
30 ITEA 43323
40 CRM 25200
dno만 그룹바이 해도 되지만 dname를 한 이유는 select절의 일반컬럼에 dno, dname 둘다 있기 때문에 dname도 그룹바이절에 적어준다.
예제 5. 부서별로 급여 평균의 최대 값과 최소 값을 검색한다.
SELECT dno 부서번호,
MAX(AVG(sal)) 최대평균, MIN(AVG(sal)) 최소평균
FROM emp
GROUP BY dno;
SELECT dno 부서번호,
*
1행에 오류:
ORA-00937: 단일 그룹의 그룹 함수가 아닙니다
SELECT MAX(AVG(sal)), MIN(AVG(sal))
FROM emp
GROUP BY dno;
MAX(AVG(SAL)) MIN(AVG(SAL))
------------- -------------
4070 2100
SELECT d.dno, dname, eno, ename, sal
FROM emp e, dept d
WHERE d.dno=e.dno
AND (d.dno, sal) IN (SELECT dno, MIN(sal)
FROM emp
GROUP BY dno)
ORDER BY d.dno;
DNO DNAME ENO ENAME SAL
------- ------- ------- ---------- ----------
01 총무 0202 손하늘 3510
02 회계 0309 김선유 900
10 ERP 0269 권나현 2600
20 ISP 2002 제갈민 1520
30 ITEA 2007 이초록 1989
40 CRM 2008 윤고은 2100
실습 1. 각 학과별 학생 수를 검색한다.
SELECT major 학과, COUNT(sno)
FROM student
GROUP BY major;
학과 COUNT(SNO)
------- ----------
화학 17
유공 18
생물 17
식영 19
물리 16
2. 화학과와 생물학과 학생 4.5 환산 평점의 평균을 각각 검색한다.
SELECT major 학과, TO_CHAR(AVG(avr*4.5/4), '90.99') "4.5 환산평균"
FROM student
WHERE major IN ('화학', '생물')
GROUP BY major;
학과 4.5 환산평균
------- ------------
화학 2.45
생물 2.76
3. 부임일이 10년 이상 된 직급별(정교수, 조교수, 부교수) 교수의 수를 검색한다. ♠♠♠
SELECT orders 직위, COUNT(orders) "부임일이 10년 이상 교수 수"
FROM professor
WHERE (TO_CHAR(sysdate, 'YYYY')-TO_CHAR(hiredate, 'YYYY')+1)>=10
GROUP BY orders;
직위 부임일이 10년 이상 교수 수
------- --------------------------
조교수 7
정교수 8
부교수 9
4. 과목명에 화학이 포함된 과목의 학점수 총합을 검색한다.
SELECT cname 과목이름, SUM(st_num) 학점수총합
FROM course
WHERE cname LIKE '%화학%'
GROUP BY cname;
과목이름 학점수총합
------------ ----------
무기화학 2
환경화학 2
일반화학실험 2
일반화학 3
핵화학 3
식품화학 3
유기화학 3
5. 화학과 학생들의 기말고사 성적을 성적순으로 검색한다. //같은 사람이 여러번 나오는데... 어떻게 하징... 평균내야하나...
SELECT major 학과, s.sno 학번, sname 이름, TO_CHAR(AVG(result), 90.99) 기말고사평균성적
FROM student s, score r, course c
WHERE major = '화학'
AND s.sno=r.sno AND r.cno=c.cno
GROUP BY major, s.sno, sname
ORDER BY TO_CHAR(AVG(result), 90.99) DESC;
학과 학번 이름 기말고사평균
------- ------- ---------- ------------
화학 915301 정동상 73.30
화학 925306 김재백 73.15
화학 905302 정욱상 72.85
화학 925305 황현정 72.63
화학 945303 남궁경아 70.86
화학 945314 이철윤 70.59
화학 915304 권보수 69.50
6. 학과별 기말고사 평균을 성적순으로 검색한다.
SELECT major 학과, TO_CHAR(AVG(result), 90.99) 기말고사평균
FROM student s, score r, course c
WHERE s.sno=r.sno AND r.cno=c.cno
GROUP BY major
ORDER BY TO_CHAR(AVG(result), 90.99) DESC;
학과 기말고사평균
------- ------------
식영 69.99
유공 69.56
화학 69.44
물리 68.92
생물 67.93
7. 30번 부서의 업무별 연봉의 평균을 검색한다. (단 출력 양식은 소수이하 두 자리까지 통일된 형식으로 출력한다.)
SELECT dno 부서번호, job 업무, TO_CHAR(AVG(sal*12+NVL(comm,0))) 평균연봉
FROM emp
WHERE dno = 30
GROUP BY dno, job;
부서번호 업무 평균연봉
--------- ------- -----------
30 모델링 51600
30 개발 39184
8. 물리학과 학생 중에 학년별로 성적이 가장 우수한 학생의 평점을 검색한다.
SELECT major 학과, syear 학년, TO_CHAR(MAX(avr), 90.99) 성적
FROM student
WHERE major = '물리'
GROUP BY major, syear
ORDER BY syear;
학과 학년 성적
------- ---------- ------------
물리 1 3.20
물리 2 3.22
물리 3 4.00
물리 4 3.33
9. 학년별로 환산 평점의 평균값을 검색한다.
(단 출력 양식은 소수이하 두 자리까지 통일된 양식으로 출력한다.)
SELECT syear 학년, TO_CHAR(AVG(avr*4.5/4), 90.99) 성적
FROM student
GROUP BY syear
ORDER BY syear;
학년 성적
---------- ------------
1 3.13
2 2.97
3 3.08
4 2.85
10. 화학과 1학년 학생 중 평점이 평균 이하인 학생을 검색한다.
SELECT major 학과, syear 학년, sno 학번, sname 이름, TO_CHAR(avr, 90.99) 성적
FROM student
WHERE major='화학' AND syear=1
AND avr <= (SELECT AVG(avr) FROM student
WHERE major='화학' AND syear=1);
학과 학년 학번 이름 성적
------- ---------- ------- ---------- ------------
화학 1 945303 남궁경아 2.36
화학 1 945314 이철윤 2.22
httpd.conf 에서 extra/httpd-vhosts.conf 파일에 대한 include 설정이 필요하다.
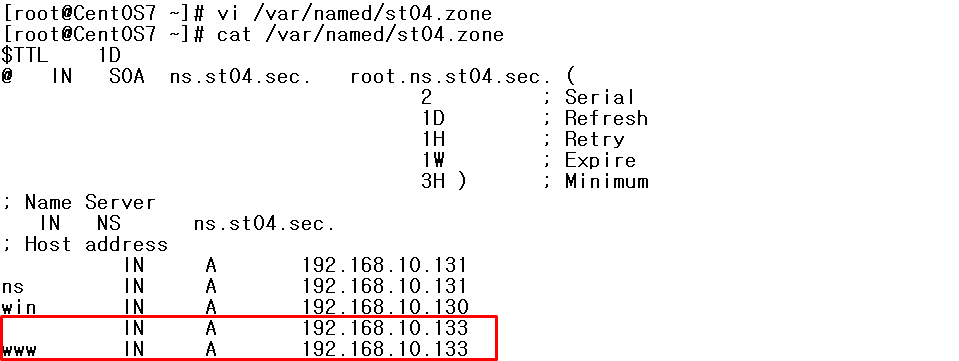
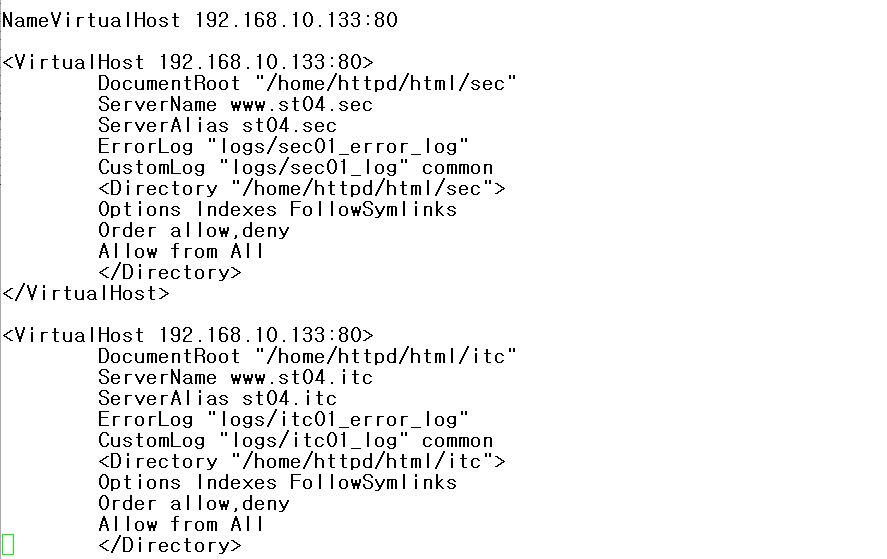
주의 사항 • 호스팅 디렉토리에 대한 접근 설정이 유효 //해당 디렉토리 퍼미션 있어야함 • conf/extra/httpd-vhosts.conf를 참고 • apache 설정보다 name server설정이 우선 • 호스팅 중인 호스트명이 name 서버에서 확인 • 시스템의 호스트명과 /etc/hosts에 기록된 이름이나 IP를 동일하게 설정
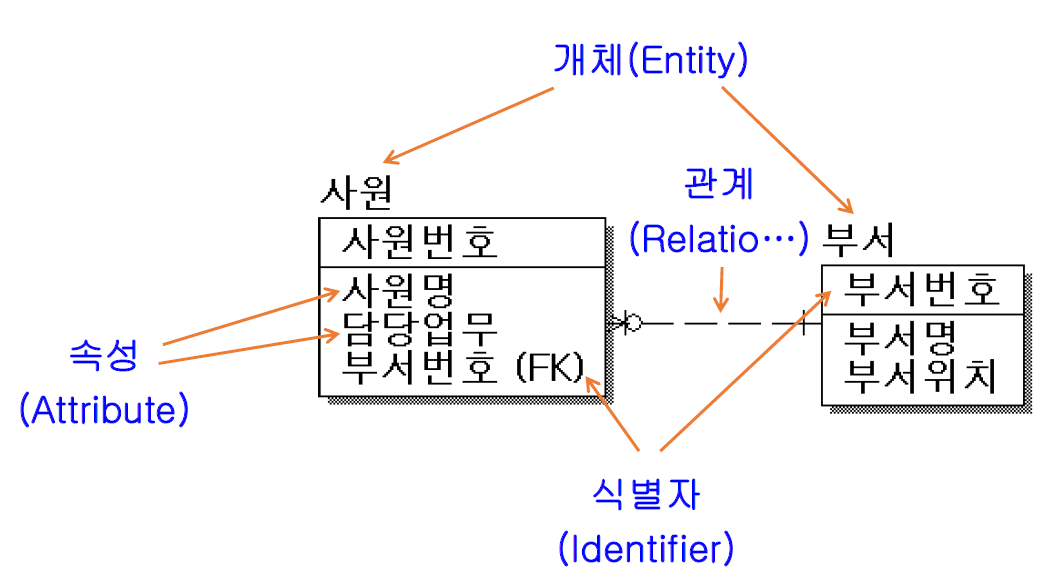
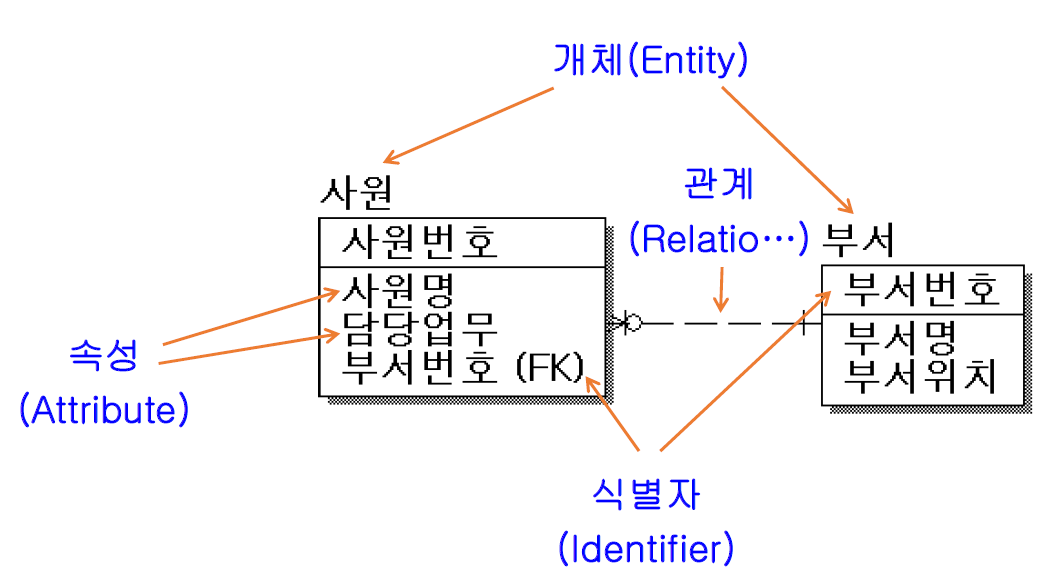
• 특징 ‐ 상호 배타성 :모든 인스턴스은 하나의 개체에만 속해야 한다. ‐ 식별성 :모든 인스턴스는 식별자에 의해 식별 가능해야 한다. ‐ 반드시 둘 이상의 속성을 포함해야 한다. ‐ 다른 개체와 반드시 관계를 갖는다.
• 종류 ‐ 기본 개체 (핵심 개체) :사원, 부서, 고객, 상품, 학생 등과 같이 기본 정보를 포함한 개체 :정보 처리를 위해 기본적(독립적)으로 존재하는 개체 ‐ 개념 개체 :업무처리나 흐름을 위해 무형의 과정이나 개념을 위해 만들어진 개체 :공정, 상태와 같이 핵심개체의 일부로 여겨지기도 한다. ‐ 교차 개체(관련 개체) :두 개체간에 관계를 위해 만들어지는 개체 :N:M 관계를 해소하는 역할을 한다. :구매, 입고
• 구분 ‐ 상위 개체 : 하위 개체 ‐ 부모 개체 : 자식 개체 ‐ 독립 개체 : 종속 개체
개체 예시
관계(Relationship)
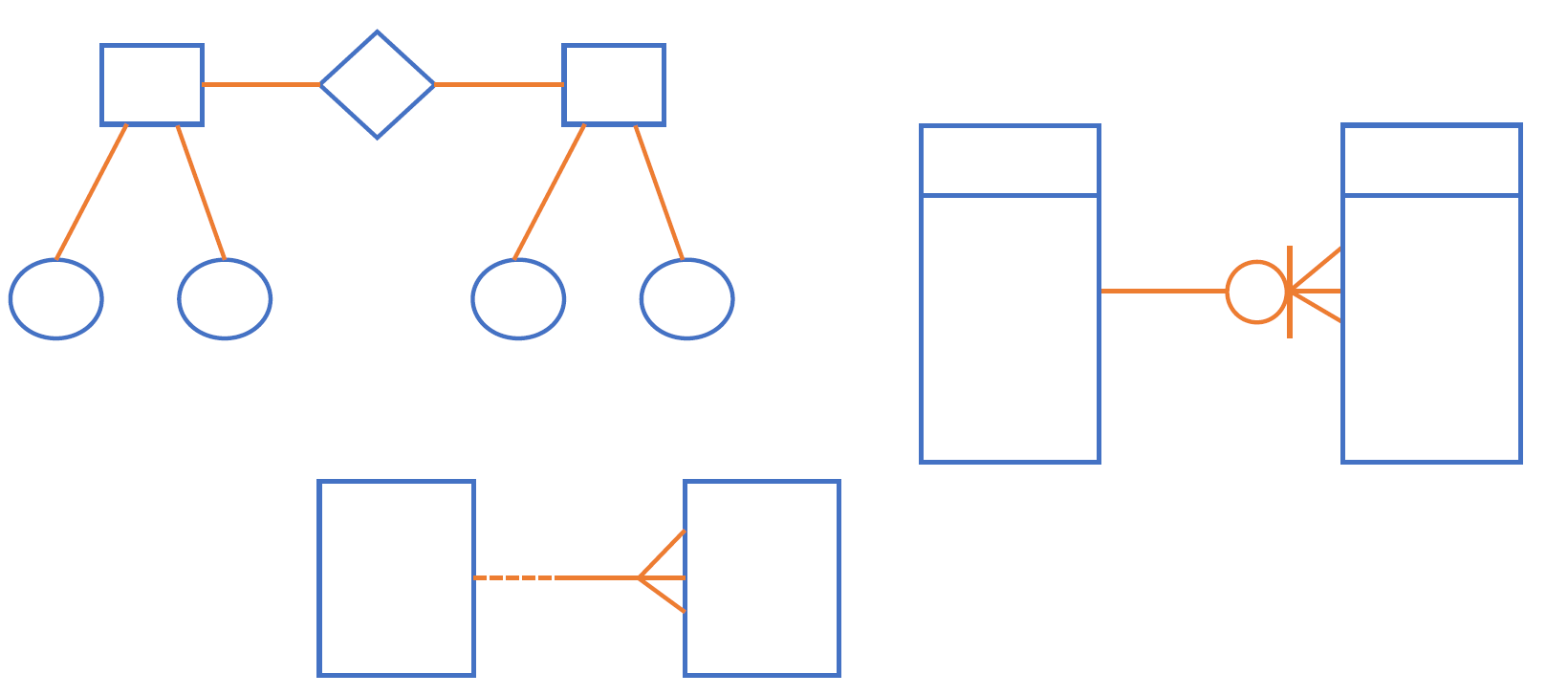
: 둘 이상의 개체 간에 명명되어진 의미있는 연결 ‐ 개체 사이에 논리적 연관성으로 존재의 형태나 행위로서 연결성이 부여된 상태 (교수 – 과목 : 교수는 과목을 강의한다.)
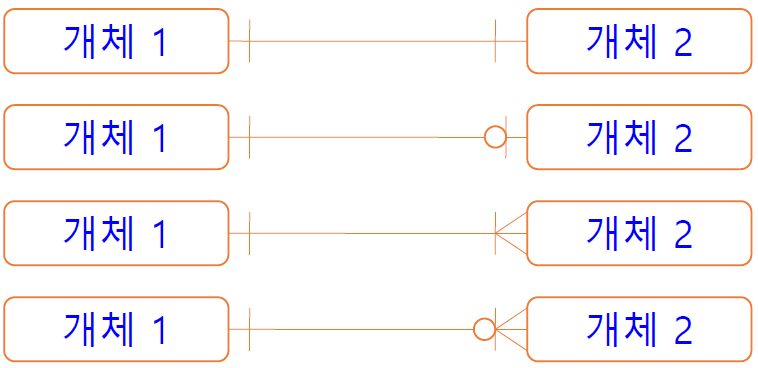
• 관계 표기 ‐ 관계명(Membership) :관계 시작점과 끝점을 갖는다. :학생(소속된다.) -- 학과(포함한다.) ‐ 관계차수(Cardinality) :1:1, 1:N, N:M (N:M 은 관계가 정의가 끝나지 않은 상태) ‐ 관계선택사양(Optionality) :필수(|) or 선택(O)
• 종류
1 : 1 관계
1 : 1 이하 관계
1 : 1 이상 관계
1 : 0 이상 관계
• 관계 항목 ‐ 개체 사이에 연관 규칙이 있는가? ‐ 개체간 정보 조합이 발생하는가? // 정보조합: 조인이나 서브쿼리 사용하는지 ‐ 개체간 관계 규칙 서술이 있는가? ‐ 관계 연결을 가능케하는 동사가 있는가?
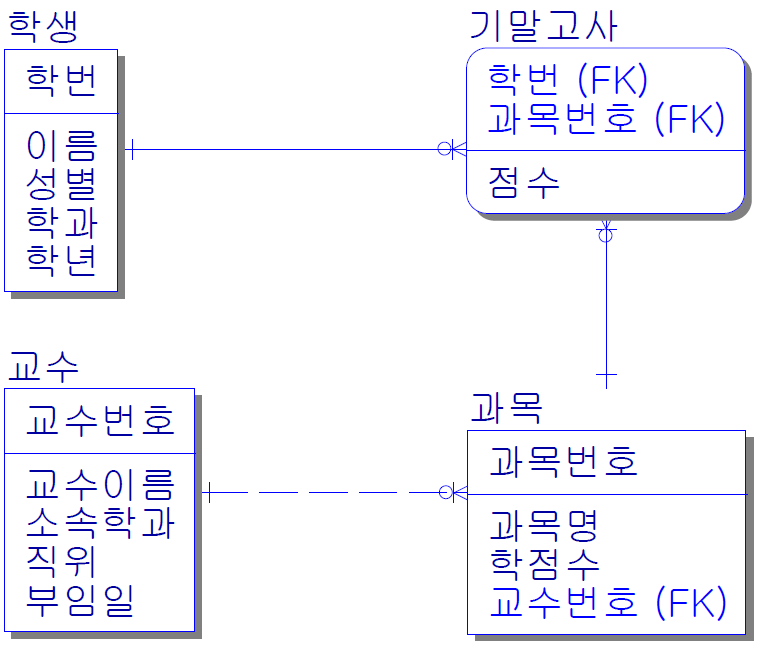
관계 예시
점선 - 비식별관계 (약한 관계) : 외래키가 일반속성에 있으면 비식별 (부서번호는 사원 테이블에 일반속성)
실선 - 식별관계 (강한 관계) : 외래키가 주식별자에 포함되어 있으면 식별 (사번은 자격면허 테이블에 주식별자)
* 외래키에는 인덱스 만들어 준다.
그러나 외래키가 주식별자에 포함되어 있으면 인덱스 안만들어도 된다.
사원 테이블 입력후 신체 테이블은 포함되어야 한다.
사원과 자격면허 테이블은 자격면허 테이블의 속성은 입력이 안될 수도 있다.
속성(Attribute)
: 개체의 성질, 수량, 상태 등을 의미하는 최소의 데이터 단위 ‐ 주 식별자에 함수적 종속 관계를 유지
• 개체, 속성, 인스턴스 관계 ‐ 개체는 두 개 이상의 인스턴스를 갖는다. ‐ 개체는 두 개 이상의 속성으로 구성된다. ‐ 한 개 속성은 한 개의 값을 갖는다.
• 종류 ‐ 기본(단순) 속성 : 사용자, 업무에 의해 추출한 모든 속성 ‐ 설계 속성 : 업무 분석 반영이나 규칙을 위해 만들어지거나 변형된 속성 ‐ 추출(파생) 속성 : 속성들로 부터 연산된 속성 ‐ 결합 속성 : 둘 이상의 속성을 편의에 의해 하나의 속성으로 관리되는 속성
• 도메인(Domain) ‐ 속성 값의 범위로 속성의 데이터 타입과 크기 제약사항 등을 기술한다.
• 속성 명명 ‐ 현장(업무, 현재)에서 사용중인 명칭 ‐ 약어나 서술식은 지양 ‐ 가급적 유일한 명칭을 이용한다.
식별자(Identifiers)
• 주식별자(Primary identifier) ‐ 개체내에 인스턴스를 유일하게 구별할 수 있어야 한다. ‐ 나머지 속성에 대해 결정인자(함수적 종속관계) ‐ 한 개의 속성이나 속성 조합으로 구성된다.(최소의 수가 돼야한다.) ‐ 특징 :Uniqueness, Not null, Unchangeability, Shot, Simple
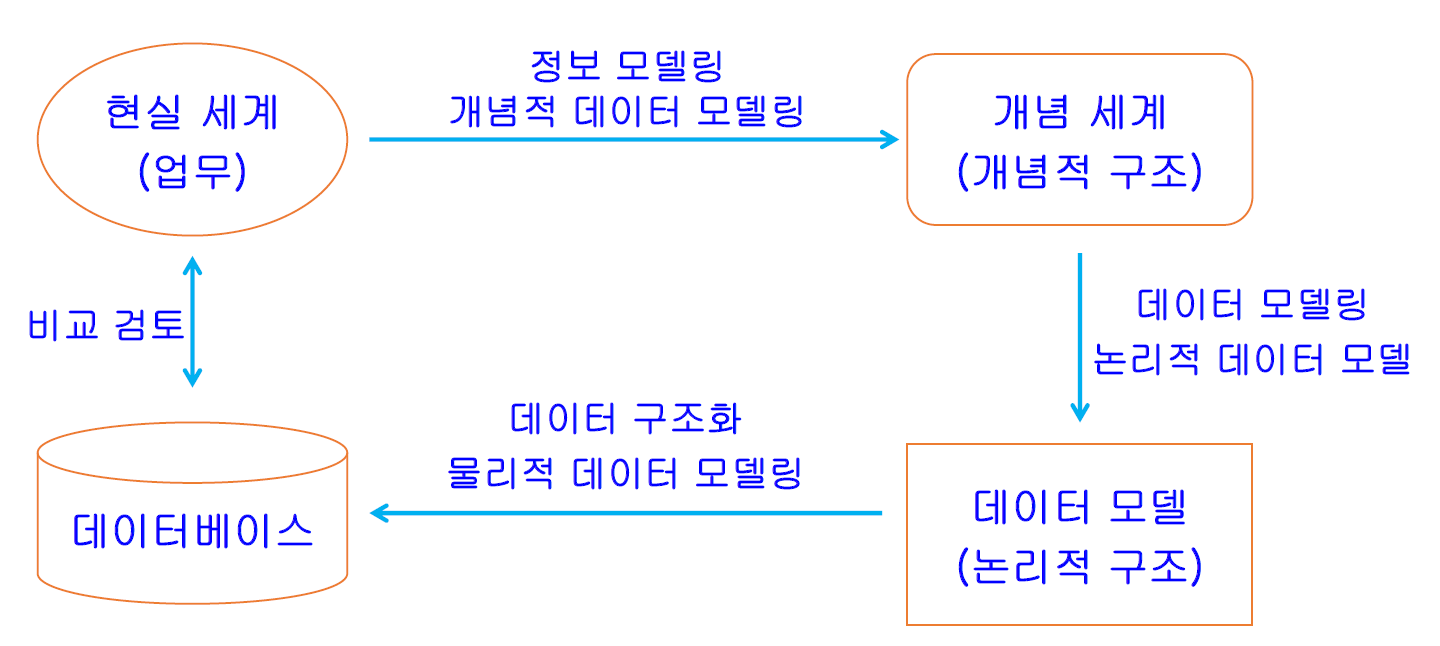
• 모델링 ‐ 현실세계의 다양한 현상을 일정한 규칙을 가진 표기법에 의해 표현하는 것 ‐ 데이터 관점 : 데이터와 데이터 간에 관계(WHAT) ‐ 프로세스 관점 : 무엇을 어떻게 해야 하는가에 대한 관점(HOW) ‐ 상관 관점 : 일이 진행되는 과정에 데이터가 받는 영향을 모델링(Interaction) • 모델링의 특징 ‐ 추상화 : 현상의 핵심적인 부분을 일정한 형식에 맞추어 표현 ‐ 단순화 : 복잡한 현상을 제한된 표현법으로 이해하기 쉽게 표현 ‐ 명확화 : 불분명한 부을 제외하고 정확히 현상을 기술하는 것
데이터 모델
• 데이터 모델 ‐ 다양한 사회 활동 특히 업무에 의해 사용되고 발생되는 데이터를 추상화한 것 • 관계형 데이터베이스와 모델링 ‐ 관계형 데이터베이스에 기반한 데이터 모델은 다음과 같은 장점을 가진다. :독립성 ,무결성, 중복 감소, 공유 가능, 표준화, 보안 • 모델링의 효과 ‐ 중복의 감소 :불 필요한 중복으로 인해 정보의 무결성이 훼손되지 않는다. ‐ 유연성 강화 :변화하는 업무 시스템을 데이터 모델이 수용할 수 있다. :데이터 구조의 안정성 ‐ 일관성 유지 :업무내에 연관된 데이터 간 무결성을 유지해준다.
현실 업무와 모델링, DB
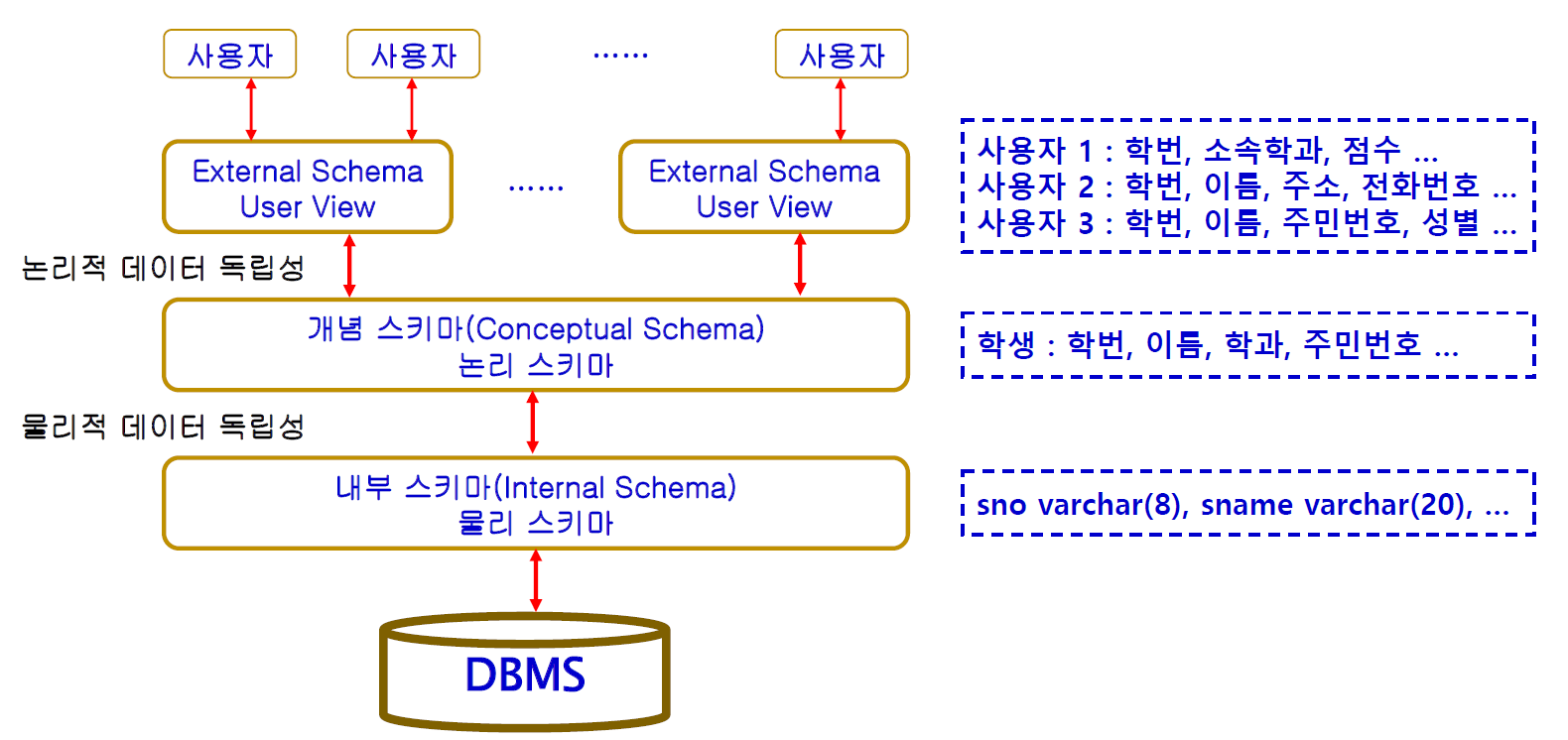
데이터 독립성과 3단계 구조
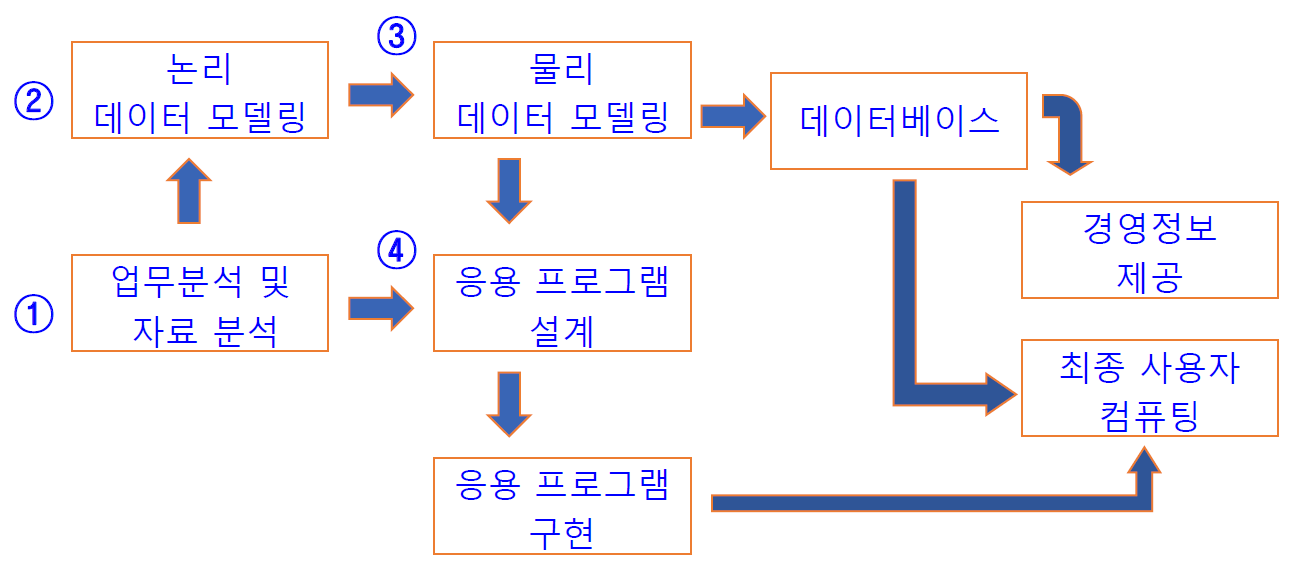
모델링과 개발 방법론 1
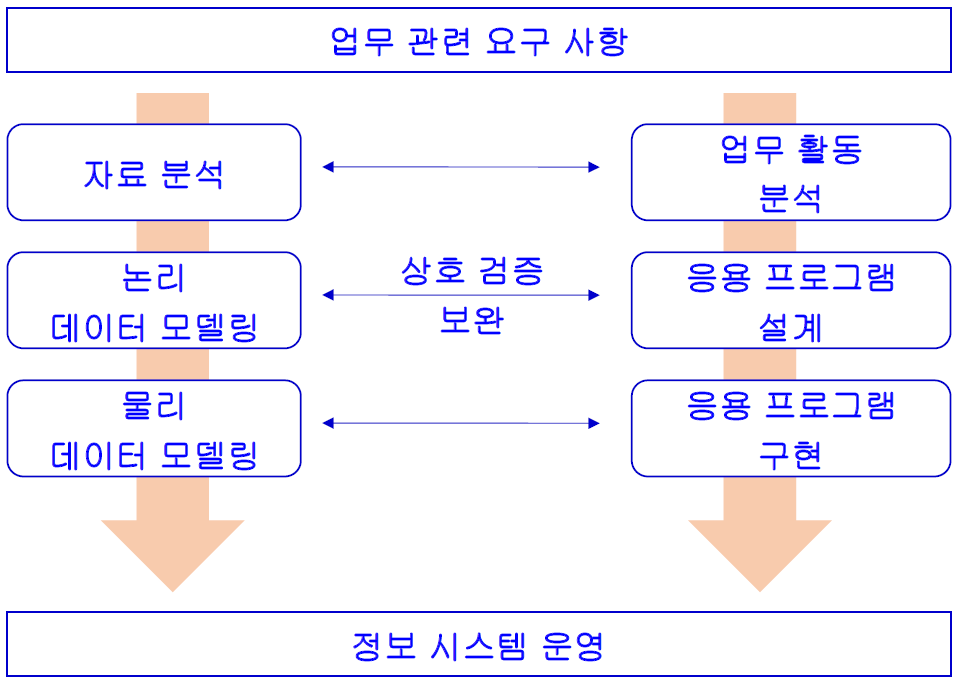
모델링과 개발 방법론 2
위 첫번째 방법론 뒤에 병렬식 방법론이 나왔다.
인력을 많이 사용해 시간비용을 줄임.
모델링 개요
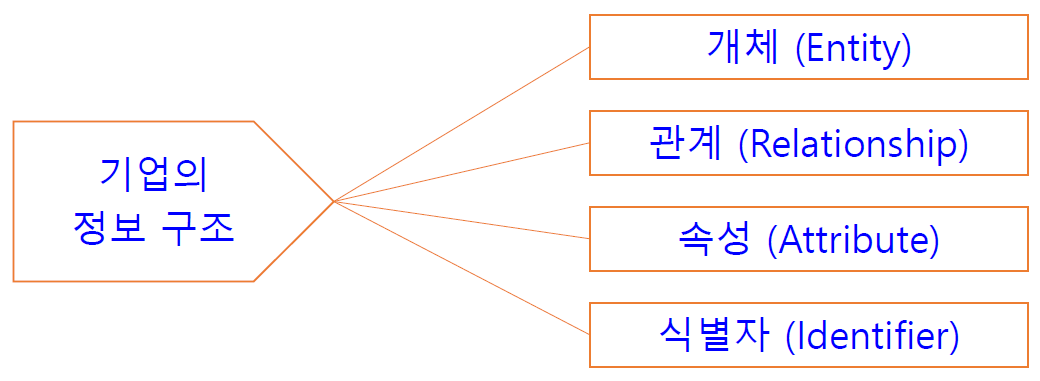
• 기업의 정보 구조를 개체(Entity)와 관계(Relationship)를 중심으로 체계적으로 표현하고 문서화하는 기법 • 정보 시스템의 중심을 데이터 관점에서 접근하는 분석 방법